
打造学术外挂大脑(三):Query语法打造智能文献检索系统
通过前两期教程,我们已经打通了Zotero文献管理与Logseq知识图谱的联动通道(点击查看往期教程1、教程2)。本文将为您解锁Logseq的Query检索功能,助您实现文献数据的精准定位与智能聚合。
Query语法核心操作指南在Zotero中建立文献标签体系后(示例标签系统如图)同步至Logseq,可通过以下逻辑运算符构建检索表达式:
逻辑与(AND)检索1{{query (and [[A方面结论]] [[属于1]] )}}
应用场景:查找同时包含”核心结论”与”分类属性”的文献检索效果:精准定位同时满足两个条件的文献条目
逻辑或(OR)检索1{{query (or [[属于1]] [[属于2]])}}
应用场景:跨分类文献普查/建立关联研究网络检索效果:获取满足任一条件的文献集合
逻辑非(NOT)嵌套检索1{{query (and [[属于1]] (not [[A方面结论]])) }}
应用场景:排除特定条件的精准筛查检索效果:获取目标分类中排除特定研究方向的文 ...

打造学术外挂大脑:Zotero+Logseq文献笔记模版进阶指南
上一篇文章介绍了如何设置Zotero与Logseq的笔记联动,本篇为大家提供文献笔记模版进阶指南。
模版功能亮点✨这个智能笔记模版可自动捕获以下核心文献信息:
📚 双语标题:智能识别中英文题目对照
👥 作者列表:自动截断超长作者团队(保留前10位+et al.)
🏷️ 期刊信息:包含影响因子分区、出版日期双维度
🔗 智能链接:自适应生成PDF本地链接与DOI/URL切换
🌐 双语摘要:优先展示翻译版本摘要,无翻译版本自动回退原文摘要
📅 时间戳记:自动生成标准化的笔记创建时间配置步骤详解⚙️前置插件安装
Ethereal Style(期刊分区展示)
基础安装过程省略
绑定EasyScholar账号获取期刊分区数据(设置方法)
Translate for Zotero(摘要翻译)
推荐使用DeepSeek(需自行申请密钥,可参照网络上的教程)
支持中英/中日等多语种互译模版代码定制
路径:Zotero 设置 → Better Notes → 模板编辑器 → 将上一篇文章我们创建的 MD笔记 模板替换为以下内容(可自定义,具体设置方法参见上篇博客)
12345 ...

打造学术外挂大脑:Zotero+Logseq联动构建论文库
“你是否经历过这样的场景:
电脑里塞满了从各个数据库下载的 PDF 文献,文件夹命名混乱到连自己都找不到;读论文时灵感迸发写下的笔记,却散落在 Zotero 注释、Word 文档和纸质笔记本之间;写论文需要引用某个关键结论时,不得不花半小时翻查’可能存放在某个地方’的笔记。
在科研领域,我们缺的从来不是知识获取渠道,而是让碎片化信息真正流动起来的系统。直到我发现 Zotero 与 Logseq 的联动组合——前者像严谨的图书馆管理员,后者则化身思维导图师,共同构建起一个自生长的学术知识库。
尽管 Logseq 内置支持 Zotero 文献关联,但存在两个关键瓶颈:笔记同步割裂:Zotero 中的笔记修改后无法自动同步到 Logseq,需反复手动导入。格式兼容障碍:导出的笔记以纯文本块形式存在,无法继承 Markdown 语法特性,导致双向链接失效
本文方案通过 Zotero Better Notes 插件 能够实现:✅ 保留 Markdown 原生语法(标签、双向链接)✅ 建立 Zotero→Logseq 的单向自动同步通道✅ 兼容 Logseq 日期日志关联机制
所需工具
Zote ...

跨语言协作指南:如何通过rpy2无缝转换R变量至Python字典
背景需求在数据科学实践中,我们经常需要整合不同语言的优势资源。本文将聚焦一个典型场景:将R语言的计算成果迁移至Python环境进行后续处理或可视化。通过rpy2工具包,我们可以实现变量结构的完整保留与高效转换。
技术选型:rpy2核心优势工具定位rpy2是Python与R语言之间的双向桥梁,支持在Python环境中直接调用R函数库。其独特价值在于:
生态融合:集成CRAN超过18,000个R包
性能优化:采用内存共享机制减少数据拷贝开销
开发效率:支持Jupyter Notebook实时交互核心功能矩阵
功能维度
具体实现
代码互操作
支持在Python中执行R代码块,调用ggplot2、dplyr等经典库
数据转换
自动处理numpy数组与R矩阵、pandas.DataFrame与data.frame的类型转换
可视化整合
在Jupyter中直接渲染R图形输出(支持ggplot2、lattice等可视化库)
扩展能力
提供C扩展接口,支持并行计算加速
环境准备12345# 前置条件:已配置R语言环境(建议4.0+版本)# 验证R_HOME环境变量echo ...
解决每次 unraid 重启以后 immich 账户丢失问题
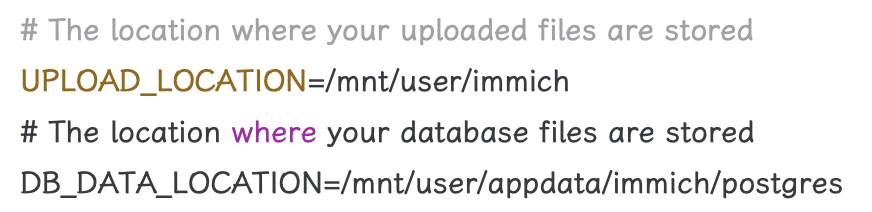
最近购入了一台天钡 Wtr pro amd 版,安装 unraid 后部署了最新版 immich,但是发现每次重启 unraid 后 immich 的账户都会丢失。经排查发现是 env 文件中 DB_DATA_LOCATION 设置错误导致的。
错误设置为:
1234# The location where your uploaded files are storedUPLOAD_LOCATION=/mnt/user/immich# The location where your database files are storedDB_DATA_LOCATION=/volumn1/...
正确设置为
1234# The location where your uploaded files are storedUPLOAD_LOCATION=/mnt/user/immich# The location where your database files are storedDB ...

解决python-wordpress-xmlrpc上传文章后发布时间为8小时后
上篇文章介绍了如何使用 Python 自动上传更新 Markdown 格式的文章到 WordPress,但是上传后发现发布时间总是在设定时间的8小时以后。搜索了很多方法都不起作用,所以简单粗暴,上传的时候直接时间减8小时即可。
12from datetime import timedeltapost_modified_date = post_modified_date - timedelta(hours = 8)
这样处理似乎通用性欠佳,因为我们能确定这个问题和时区有关,因此可按照本地时区确定 timedelta。
tzlocal.get_localzone().key 获取当前系统时区名
pytz.timezone(时区名) 将时区名转换成时区信息
datetime.now(时区信息).utcoffset() 获取当前时区和 UTC 时区的偏移量 timedelta123import tzlocalimport pytzlocal_timedelta = datetime.now(pytz.timezone(tzlocal.get_localzone().key)).utcoff ...
使用Python自动上传或更新Markdown文章到WordPress
工具
python-wordpress-xmlrpc
python-markdown
python-frontmatter思路Markdown 写文章免除了排版的苦恼,适合简单记录。以前使用 Hexo 发布文章,在开头往往需要打上分类、标签等方便查找。我一般使用 Jekyll-style YAML 格式在 Markdown 文件开头建立元数据,如下图所示。现在我要同时发布文章到 Hexo 和 WordPress,查找了些资料,整理出一个 Markdown 直接发布到 WordPress的思路:
使用 python-frontmatter 库识别 Jekyll-style YAML 格式文件的元数据和内容。
使用 python-markdown 将 Markdown 格式内容转换成 Html 形式。
使用 python-wordpress-xmlrpc 调用 WordPress 的 xmlrpc 接口进行文章上传、修改等操作。代码获取 Markdown 文件数据12345678910111213141516171819import datetimeimport frontmatteri ...

将博客从 Hexo 迁移到 Wordpress
写在前面博客很久没有更新了。一方面是由于本人并不是计算机从业人员,编程只是个人爱好,疫情期间过于忙碌,没有精力做工作以外的任何事情。另一方面是人到中年,有太多更加重要的事情需要去做。最近有些闲暇时间,发现原来的博客在新版 Hexo 下还能很好的运行,遂重新捡起来,写篇博客聊以纪念。
迁移也不能算迁移,因为看到 Wordpress 建站的优点,想尝试一下,又没有内容,所以索性把旧博客的内容搬到 Wordpress,网址是:blog.yeureka.cn。本次迁移参考了 onekyle 的 HexoToWordPress 库。代码非常简单,只需两步:
将 md 中的信息抽取
将获得的信息发布到 Wordpress
onekyle 已经把完全写好了这两步需要用的方法,直接调用即可。需要注意的是,该仓库用到的 frontmatter 库名为 python-frontmatter,注意不要安装错即可。
代码1234567891011121314import osfrom blog_uploader.markdown_parser import parse_markdownfrom blog_ ...
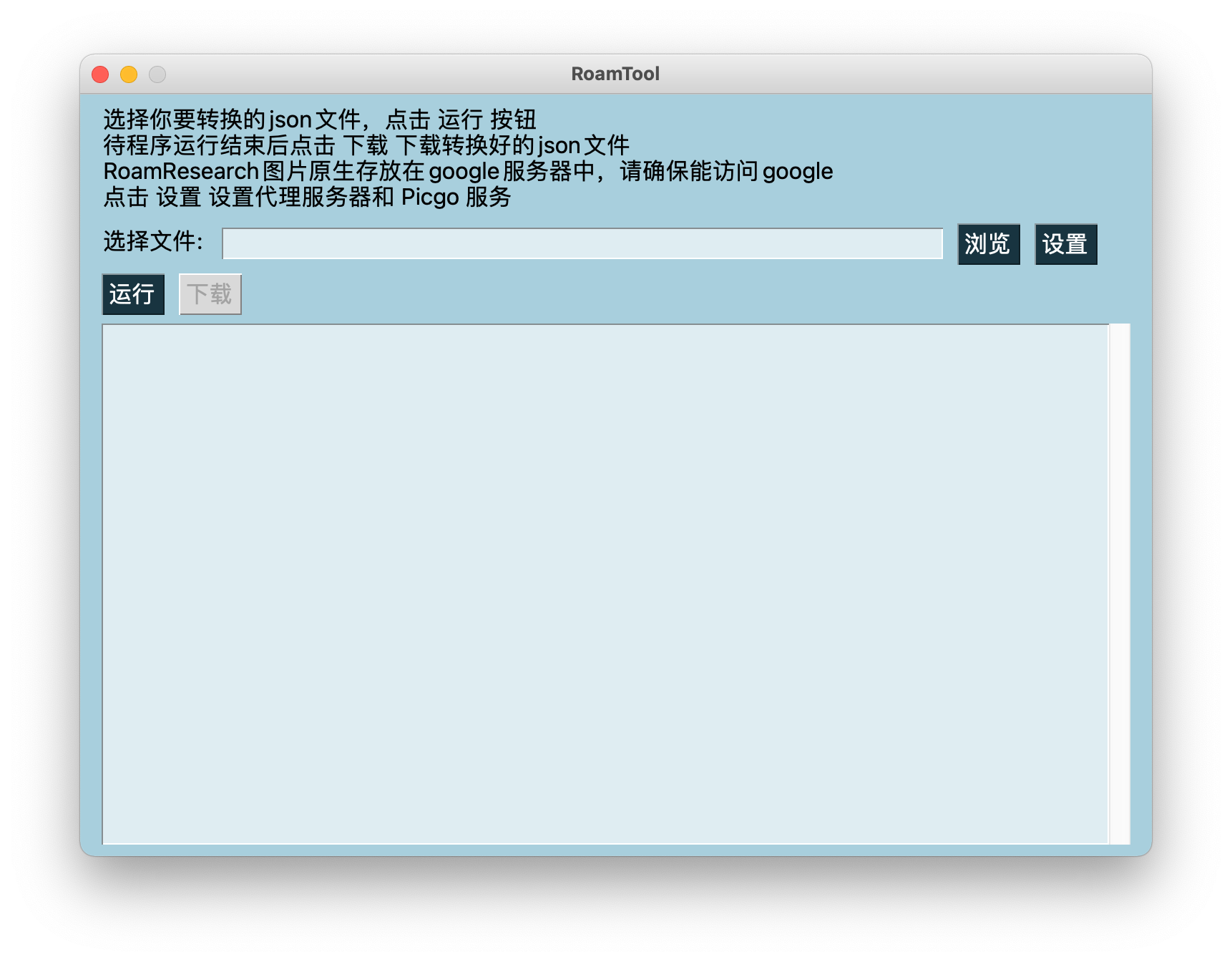
Roam Research图片链接一键替换保存工具
缘由由于Roam的调整,无法加载http链接图片,只能加载https链接图片,而本人RoamResearch中的图片存放在七牛云,https链接需要收费,因此转用又拍云,需要将笔记中所有图片链接转换到又拍云。
功能说明下载RoamResearch的图片并利用Picgo上传到新图床备份,同时用新图床链接替换原有图片链接,生成新的json文件可重新导入RoamResearch中。
依赖
requests
pysimplegui
Picgo使用方法下载安装1234567# 下载并进入文件夹git clone https://github.com/yeureka/RoamTools.gitcd RoamTools# 使用 pipenv 安装虚拟环境pipenv install# 打开python RoamToolUI.py
使用前准备首先需要将RoamResearch文章导出为json格式文件。然后打开本工具。由于RoamResearch原生图片存放在google,众所周知的原因下载这些图片需要使用代理。点击设置按钮可设置代理服务ip。12345678 ...
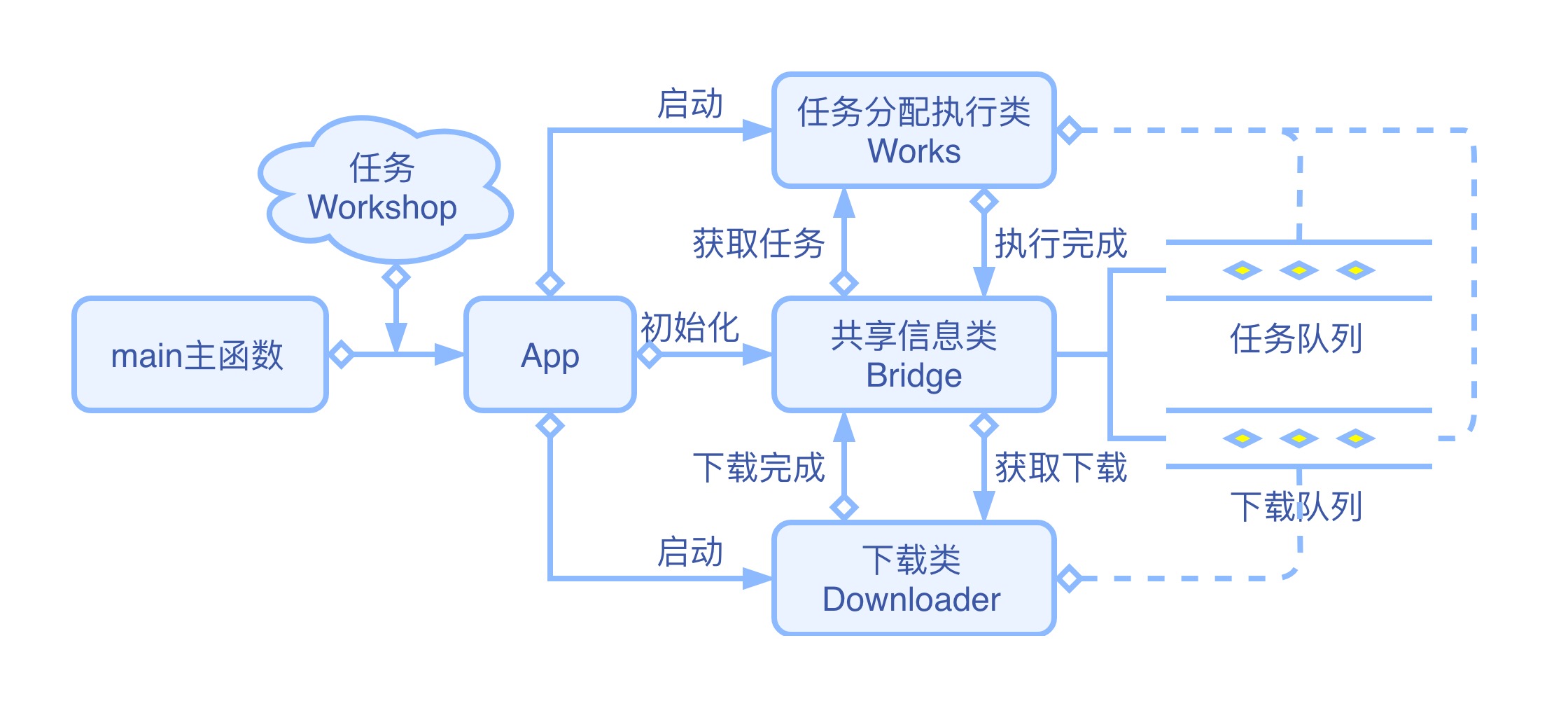
Python进程+协程——从零开始搭建异步爬虫(2)
在上节中,我们成功的在多进程中利用协程实现了多任务异步执行和多流程按次序执行的目标。本节我们将在原有代码的基础上继续改造代码,增加网页请求功能,实现一个简单的异步爬虫,实现每次爬新网页只需要关注网络请求、网页解析和数据处理,多进程和异步请求部分由爬虫自身处理。
详细流程图
需要用到的库Beautifulsoup:一个可以从 HTML 或 XML 文件中提取数据的Python库。
1234# 安装方法cd AiospiderWorkshoppipenv shellpipenv install beautifulsoup4
创建下载类 Downloader我们以崔庆才崔老师建立的爬虫练习网站 https://scrape.center/ 为练习对象。我们用到的是其中最简单的一个网页 https://ssr1.scrape.center/page/1。阅读本节需要对 Beautifulsoup 库和 aiohttp 库有简单了解。
新建一个 py 文件,验证下载类 Downloader 的功能。
建立一个函数备用,从网页抽取电影名并打印到屏幕上。
1234567from bs4 im ...