在上节中,我们成功的在多进程中利用协程实现了多任务异步执行和多流程按次序执行的目标。本节我们将在原有代码的基础上继续改造代码,增加网页请求功能,实现一个简单的异步爬虫,实现每次爬新网页只需要关注网络请求、网页解析和数据处理,多进程和异步请求部分由爬虫自身处理。
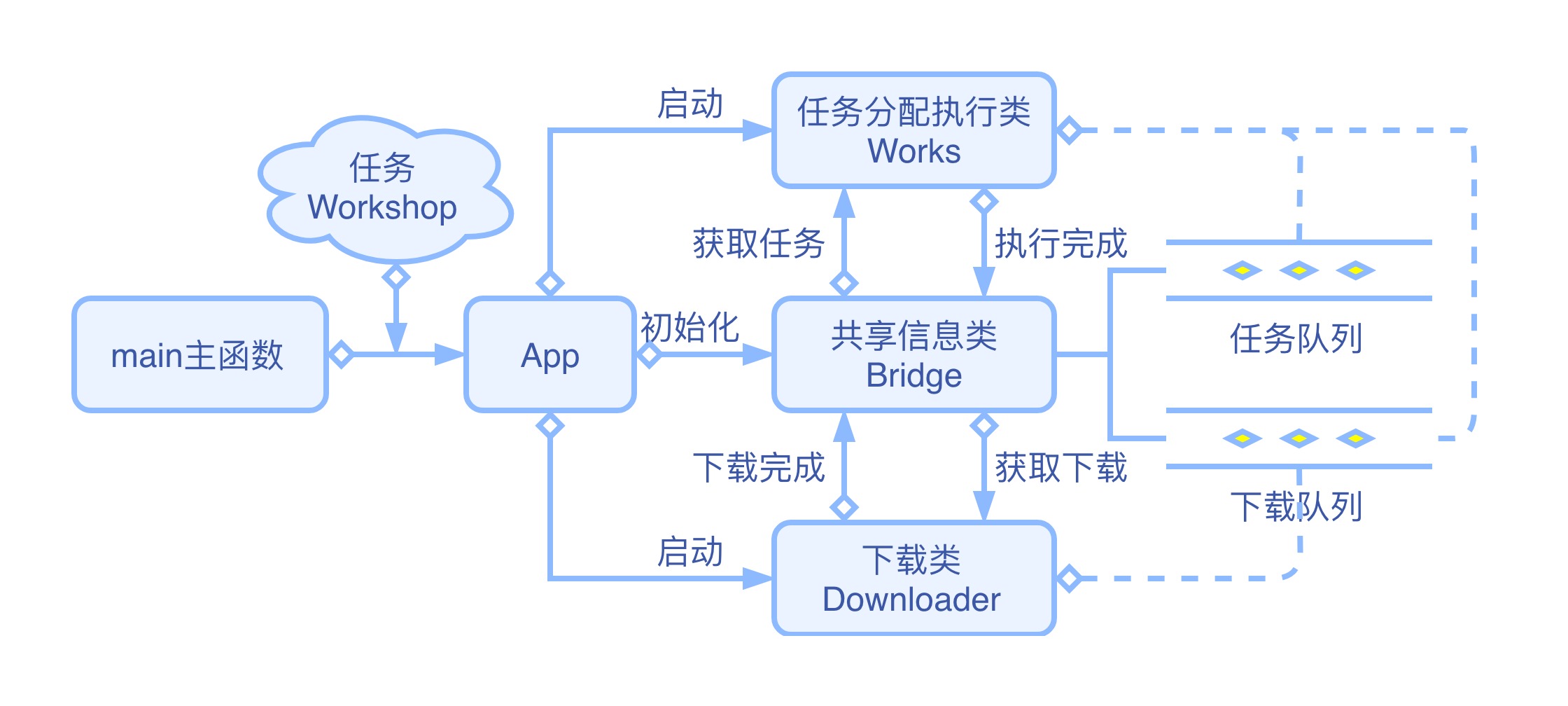
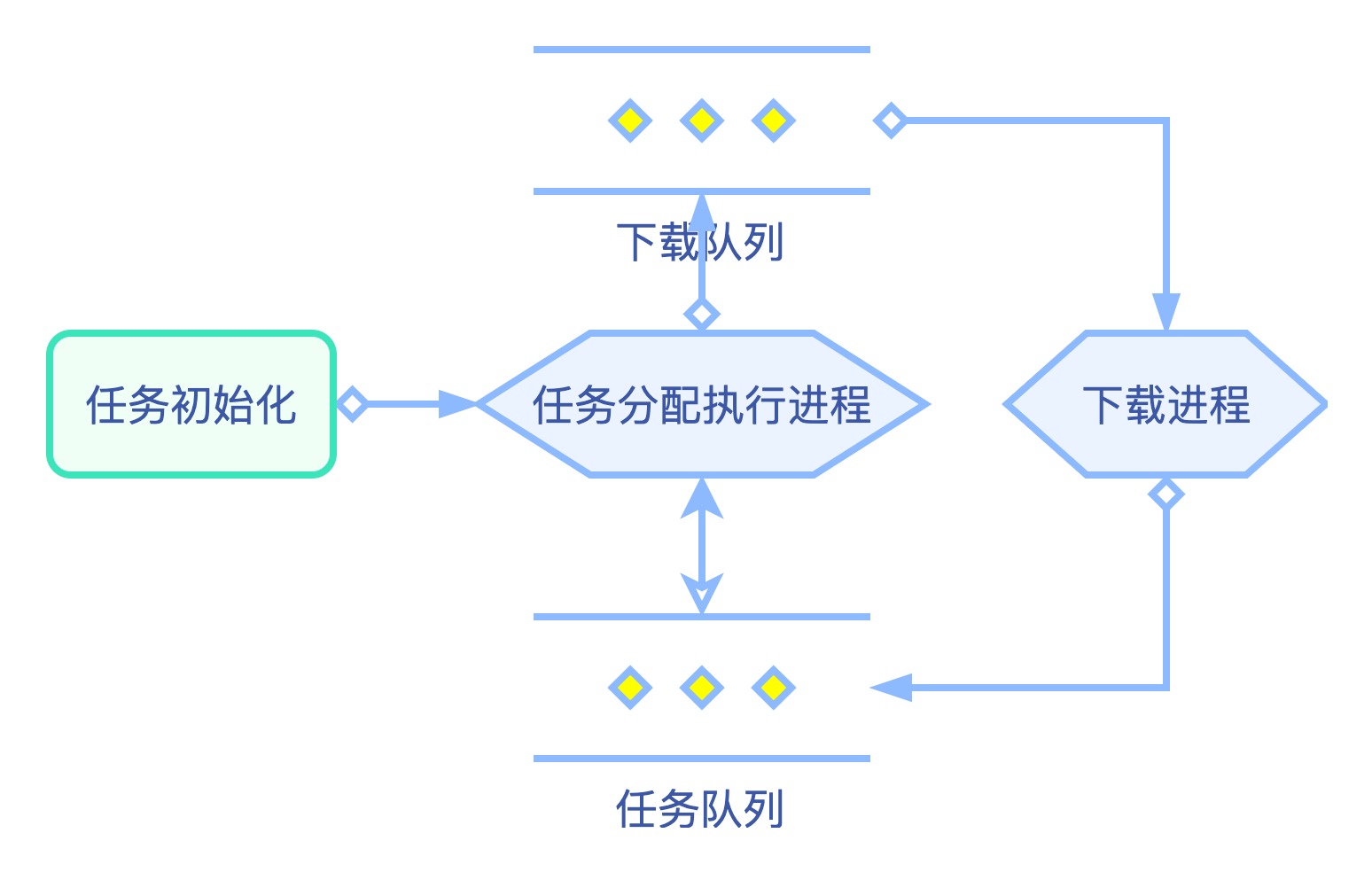
详细流程图
需要用到的库 Beautifulsoup:一个可以从 HTML 或 XML 文件中提取数据的Python库。
1 2 3 4 # 安装方法 cd AiospiderWorkshop pipenv shell pipenv install beautifulsoup4
创建下载类 Downloader 我们以崔庆才崔老师建立的爬虫练习网站 https://scrape.center/https://ssr1.scrape.center/page/1Beautifulsoup 库和 aiohttp 库有简单了解。
新建一个 py 文件,验证下载类 Downloader 的功能。
建立一个函数备用,从网页抽取电影名并打印到屏幕上。
1 2 3 4 5 6 7 from bs4 import BeautifulSoupdef extract_movie_name (html ): soup = BeautifulSoup(html, "html.parser" ) name_tags = soup.find_all(class_="m-b-sm" ) for name_tag in name_tags: print(name_tag.string)
创建下载类 Downloader
Downloader 类主要有两个方法 get_async、download。
download:打开一个 session,异步请求 url 列表中的所有 url。
get_async:请求网页并返回网页 html。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import asynciofrom aiohttp import ClientSessionclass Downloader : async def get_async (self, session, url ): async with session.get(url=url) as resp: return await resp.text() async def download (self ): async with ClientSession() as session: url_lst = [ "https://ssr1.scrape.center/page/1" , "https://ssr1.scrape.center/page/2" ] download_tasks = list () for url in url_lst: download_task = asyncio.create_task(self.get_async(session, url)) download_tasks.append(download_task) for task in download_tasks: await task result = task.result() extract_movie_name(result) def async_run (self ): asyncio.run(self.download())
编写主函数 main
1 2 3 if __name__ == "__main__" : downloader = Downloader() downloader.async_run()
此时,下载类能够正常运行。
1 2 3 4 5 # 运行结果 霸王别姬 - Farewell My Concubine 这个杀手不太冷 - Léon 肖申克的救赎 - The Shawshank Redemption ...
整合下载类 目前我们的下载类还是一个单独的功能,我们需要将下载方法整合进现有代码,采用多进程方法调用下载方法,并通过下载队列交换数据。
改造 Bridge 类
增加下载队列相关功能,原有代码不变。
download_queue:下载队列。
put_download_queue、get_download_queue、download_queue_empty 的功能不言自明。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Bridge : def __init__ (self ): manager = Manager() self.download_queue = manager.Queue() def put_download_queue (self, workshop ): self.download_queue.put_nowait(workshop) def get_download_queue (self ): return self.download_queue.get_nowait() def download_queue_empty (self ): return self.download_queue.empty()
改造 Workshop 类
增加 url、need_download、html 三个属性
1 2 3 4 5 6 class Workshop : def __init__ (self, url, need_download ): self.url = url self.need_download = need_download self.html = None self._next_process = None
改造 MyWorkshop 类
依据 Workshop 类的改变修改初始化代码,用本节的 extract_movie_name 方法稍加改造代替上节的两段模拟代码。
1 2 3 4 5 6 7 8 9 10 11 class MyWorkshop (Workshop ): def __init__ (self, url, need_download ): super ().__init__(url, need_download) self.set_start_process(self.extract_movie_name) async def extract_movie_name (self ): soup = BeautifulSoup(self.html, "html.parser" ) name_tags = soup.find_all(class_="m-b-sm" ) for name_tag in name_tags: print(name_tag.string) self.set_end()
改造 Downloader 类
改造 async_run、__init__ 方法,使其可以接收信息传递类 Bridge 并保存。
增加 get_page 方法:接收 workshop,取出 url 交给 get_async 下载,下载好的 html 保存在 workshop 的 html 属性,之后置 workshop 的 need_download 属性为 False,返回 workshop 。
修改 download 方法:和 works 一样采用 bridge.work_end() 判断是否程序结束,从 download_queue 下载队列中取得 workshop,交给 get_page 方法处理,返回的 workshop 放入任务队列 work_queue 中进行下一步处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Downloader : def __init__ (self ): self.bridge = None async def get_async (self, session, url ): async with session.get(url=url) as resp: return await resp.text() async def get_page (self, session, workshop ): workshop.html = await self.get_async(session, workshop.url) workshop.need_download = False return workshop async def download (self ): while not self.bridge.work_end(): async with ClientSession() as session: download_tasks = list () while not self.bridge.download_queue_empty(): workshop = self.bridge.get_download_queue() task = asyncio.create_task(self.get_page(session, workshop)) download_tasks.append(task) for task in download_tasks: await task workshop = task.result() self.bridge.put_work_queue(workshop) def async_run (self, bridge ): self.bridge = bridge asyncio.run(self.download())
改造 Works 类
修改 run_works 方法:从 work_queue 拿到 workshop 后,判断其是否需要下载,如果需要下载就推入下载队列 download_queue 让下载进程下载。
其余部分保持不变。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Works : async def run_works (self ): self.bridge.flag_start() while not self.bridge.work_end(): task_lst = list () while not self.bridge.work_queue_empty(): workshop = self.bridge.get_work_queue() if workshop.need_download: self.bridge.put_download_queue(workshop) continue task = asyncio.create_task(workshop.run_next_process()) task_lst.append(task) for task in task_lst: await task self.distribute_works(task)
改造 App 类
下载进程作为一个新进程调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class App : def __init__ (self ): self.works = Works() self.bridge = Bridge() self.download = Downloader() def async_run (self, workshop_lst ): self.bridge.init_works(workshop_lst) p_run_works = Process(target=self.works.async_run, args=(self.bridge,)) p_download = Process(target=self.download.async_run, args=(self.bridge,)) p_run_works.start() p_download.start() p_run_works.join() p_download.join()
改造主函数 main
在主函数中生成 Workshop 的列表,交给 App 执行即可。
1 2 3 4 5 6 7 8 9 10 if __name__ == "__main__" : work_lst = list () url_template = "https://ssr1.scrape.center/page/{}" for i in range (1 , 11 ): url = url_template.format (str (i)) work_lst.append( MyWorkshop(url=url, need_download=True ) ) app = App() app.async_run(work_lst)
至此,程序已可正常执行。
1 2 3 4 5 # 运行结果 霸王别姬 - Farewell My Concubine ... 魂断蓝桥 - Waterloo Bridge 运行时间:2.26s
本节完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 import asyncioimport timefrom functools import wrapsfrom multiprocessing import Processfrom multiprocessing import Managerfrom aiohttp import ClientSessionfrom bs4 import BeautifulSoupdef print_run_time (func ): @wraps(func ) def wrap (*args, **kwargs ): start = time.time() f = func(*args, **kwargs) end = time.time() print("运行时间:{:.2f}s" .format (end - start)) return f return wrap class Bridge : def __init__ (self ): manager = Manager() self.work_queue = manager.Queue() self.download_queue = manager.Queue() self.config_dict = manager.dict () self.init_config() def init_config (self ): self.config_dict["running_work_cnt" ] = 0 self.config_dict["work_start_flag" ] = False def init_works (self, workshop_lst ): for workshop in workshop_lst: self.put_work_queue(workshop) self.work_cnt_increase() def flag_start (self ): self.config_dict["work_start_flag" ] = True def work_end (self ): return self.config_dict["work_start_flag" ]\ and not self.config_dict["running_work_cnt" ] def work_cnt_increase (self ): self.config_dict["running_work_cnt" ] += 1 def work_cnt_decrease (self ): self.config_dict["running_work_cnt" ] -= 1 def put_work_queue (self, workshop ): self.work_queue.put_nowait(workshop) def get_work_queue (self ): return self.work_queue.get_nowait() def work_queue_empty (self ): return self.work_queue.empty() def put_download_queue (self, workshop ): self.download_queue.put_nowait(workshop) def get_download_queue (self ): return self.download_queue.get_nowait() def download_queue_empty (self ): return self.download_queue.empty() class Workshop : def __init__ (self, url, need_download ): self.url = url self.need_download = need_download self.html = None self._next_process = None def set_start_process (self, func ): self._next_process = func def set_next_process (self, func ): self._next_process = func def set_end (self ): self._next_process = "/EOF" def is_end (self ): return self._next_process == "/EOF" async def run_next_process (self ): workshop = await self._next_process() if workshop: return workshop else : return self class Works : def __init__ (self ): self.bridge = None def distribute_works (self, task ): workshop = task.result() if not workshop.is_end(): self.bridge.put_work_queue(workshop) else : self.bridge.work_cnt_decrease() async def run_works (self ): self.bridge.flag_start() while not self.bridge.work_end(): task_lst = list () while not self.bridge.work_queue_empty(): workshop = self.bridge.get_work_queue() if workshop.need_download: self.bridge.put_download_queue(workshop) continue task = asyncio.create_task(workshop.run_next_process()) task_lst.append(task) for task in task_lst: await task self.distribute_works(task) @print_run_time def async_run (self, bridge ): self.bridge = bridge asyncio.run(self.run_works()) class Downloader : def __init__ (self ): self.bridge = None async def get_async (self, session, url ): async with session.get(url=url) as resp: return await resp.text() async def get_page (self, session, workshop ): workshop.html = await self.get_async(session, workshop.url) workshop.need_download = False return workshop async def download (self ): while not self.bridge.work_end(): async with ClientSession() as session: download_tasks = list () while not self.bridge.download_queue_empty(): workshop = self.bridge.get_download_queue() task = asyncio.create_task(self.get_page(session, workshop)) download_tasks.append(task) for task in download_tasks: await task workshop = task.result() self.bridge.put_work_queue(workshop) def async_run (self, bridge ): self.bridge = bridge asyncio.run(self.download()) class App : def __init__ (self ): self.works = Works() self.bridge = Bridge() self.download = Downloader() def async_run (self, workshop_lst ): self.bridge.init_works(workshop_lst) p_run_works = Process(target=self.works.async_run, args=(self.bridge, )) p_download = Process(target=self.download.async_run, args=(self.bridge,)) p_run_works.start() p_download.start() p_run_works.join() p_download.join() class MyWorkshop (Workshop ): def __init__ (self, url, need_download ): super ().__init__(url, need_download) self.set_start_process(self.extract_movie_name) async def extract_movie_name (self ): soup = BeautifulSoup(self.html, "html.parser" ) name_tags = soup.find_all(class_="m-b-sm" ) for name_tag in name_tags: print(name_tag.string) self.set_end() if __name__ == "__main__" : work_lst = list () url_template = "https://ssr1.scrape.center/page/{}" for i in range (1 , 11 ): url = url_template.format (str (i)) work_lst.append( MyWorkshop(url=url, need_download=True ) ) app = App() app.async_run(work_lst)
本节总结 经过本节的改造,我们已经得到了一个简单的异步爬虫。针对一系列新网页,只需要继承 Workshop 类,实现自己的爬取流程代码即可。当然,目前它只能胜任最简单的工作,没有考虑错误处理、定制请求参数、代理、日志等一系列问题,这些需要在日后的使用中慢慢完善。